
AWS S3

Amazon S3 is easy-to-use object storage with a simple web service interface that you can use to store and retrieve any amount of data from anywhere on the web. Amazon S3 also allows you to pay only for the storage you actually use.
Common use cases for Amazon S3 storage include.
Backup and archive for on-premises or cloud data Content, media, and software storage and distribution Big data analytics Static website hosting Cloud-native mobile and Internet application hosting Disaster recovery
To support these use cases and many more, Amazon S3 offers a range of storage classes designed for various generic use cases: general purpose, infrequent access, and archive. To help manage data through its lifecycle, Amazon S3 offers configurable lifecycle policies. By using lifecycle policies, we can have data automatically migrate to the most appropriate storage class, without modifying application code.
In order to control who has access to our data, Amazon S3 provides a rich set of permissions, access controls, and encryption options.

Different type of storage in AWS that is
S3: Simple Storage Service used as storage cloud provided by aws, its charges for that what we use, it is object storage.
EBS: Elastic Block store which comes with the instance, only connected instance can use this storage just like C or D drive in our system, it is block storage means used to install software.
Glacier: Glacier is also Amazon S3 service which used to archive data for long-term at low cost.
Storage Gateway: It is used to store our premises data to S3 and also keep data locally
Advantage of Amazon S3
Create Buckets: Create and name a bucket that stores data. Buckets are the fundamental container in Amazon S3 for data storage. Store data in Buckets: Store an infinite amount of data in a bucket. Upload as many objects as you like into an Amazon S3 bucket. Each object can contain up to 5 TB of data. Download data: Download our data or enable others to do so. Download your data any time you like or allow others to do the same. Permissions: Grant or deny access to others who want to upload or download data into your Amazon S3 bucket. Grant upload and download permissions to specific users. Standard interfaces: Use standards-based REST and SOAP interfaces designed to work with any Internet-development toolkit.

Before Amazon S3
Bucket
Creating New bucket in different stepCreate bucket


Here we just put bucket Name as per naming policy, a region in which we creating same but are but reflect at one global region, bucket name always be unique in aws all region.

Enable versioning to keep the different version of the same file, if we need a log request for bucket access then mark it and need to mention Tag for further track cost in billing.

we cannot grant specific user permission here we have to assign same after creating the bucket, make ACK of a bucket.

The bucket is created by name Sanjeev-sample-bucket in US East region which is unique, now upload data in same bucket.

After uploading we can check
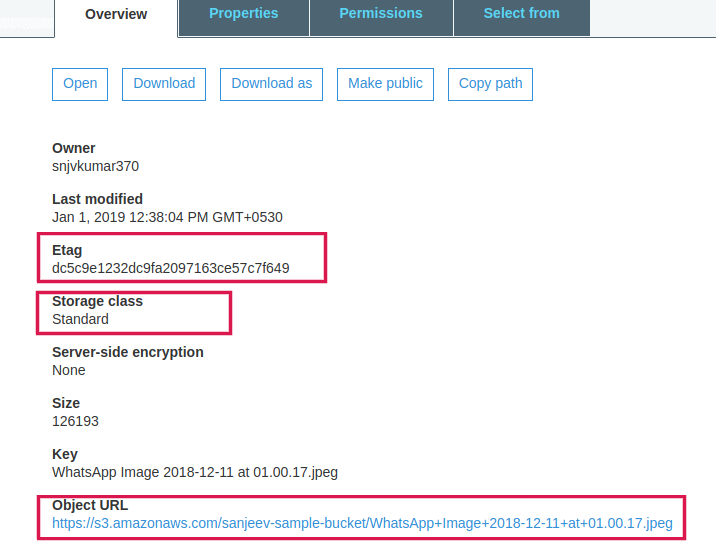
Here we can check diffrent parameter of the file uploaded like the owner, last modified, Etag which is unique for every object in the bucket, storeage class which is by default it selects standard and main thing url by which we can access or download file.
AWS S3 Bucket Restrictions and Limitations
By default, we can create up to 100 buckets in each of our AWS accounts.
If we need additional buckets, we can increase our bucket limit by submitting a service limit increase. we cannot create a bucket within another bucket. The high-availability engineering of Amazon S3 is focused on get, put, list, and delete operations.
Rules for Bucket Naming
All bucket names comply with DNS naming conventions.
Bucket names must be at least 3 and no more than 63 characters long.
Bucket names must be a series of one or more labels. Adjacent labels are separated by a single period (.). Bucket names can contain lowercase letters, numbers, and hyphens. Each label must start and end with a lowercase letter or a number.
Bucket names must not be formatted as an IP address (e.g., 192.168.5.4).
AWS S3 Features
Reduced Redundancy Storage:
Customers can store their data using the Amazon S3 Reduced Redundancy Storage (RRS) option. RRS enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of redundancy than Amazon S3 standard storage.
RRS provides 99.99% durability of objects over a given year. This durability level corresponds to an average expected loss of 0.01% of objects annually.
2. Bucket Policies:
Bucket policies provide centralized access control to buckets and objects based on a variety of conditions, including Amazon S3 operations, requesters, resources, and aspects of the request (e.g., IP address)
An account can grant one application limited read and write access, but allow another to create and delete buckets as well. An account could allow several field offices to store their daily reports in a single bucket, allowing each office to write only to a certain set of names (e.g. “Nevada/*” or “Utah/*”) and only from the office’s IP address range.
Only the bucket owner is allowed to associate a policy with a bucket.
3. AWS Identity and Access Management:
For example, we can use IAM with Amazon S3 to control the type of access a user or group of users has to specific parts of an Amazon S3 bucket.
4. Managing Access with ACLs:
Access control lists (ACLs) are one of the resource-based access policy options. You can use to manage access to your buckets and objects. You can use ACLs to grant basic read/write permissions to other AWS accounts.
There are limits to managing permissions using ACLs. For example, you can grant permissions only to other AWS accounts, you cannot grant permissions to users in your account. You cannot grant conditional permissions, nor can you explicitly deny permissions.Full_control permission to user

Amazon S3 supports a set of predefined grants, known as canned ACLs. Each canned ACL has a predefined a set of grantees and permissions.
private: Owner gets FULL_CONTROL. No one else has access rights (default).
public-read-write: Owner gets FULL_CONTROL. The All Users group gets READ and WRITE access.
aws-exec-read: Owner gets FULL_CONTROL. Amazon EC2 gets READ access to GET an Amazon Machine Image (AMI) bundle from Amazon S3.
authenticated-read: Owner gets FULL_CONTROL. The Authenticated Users group gets READ access.
bucket-owner-read: Object owner gets FULL_CONTROL. Bucket owner gets READ access. If you specify this canned ACL when creating a bucket, Amazon S3 ignores it.
bucket-owner-full-control: Both the object owner and the bucket owner get FULL_CONTROL over the object. If you specify this canned ACL when creating a bucket, Amazon S3 ignores it.
log-delivery-write: The LogDelivery group gets WRITE and READ_ACP permissions on the bucket.
5. Versioning:
Versioning enables you to keep multiple versions of an object in one bucket, for example, my-image.jpg (version 111) and my-image.jpg (version 222). we might want to enable versioning to protect yourself from unintended overwrites and deletions or to archive objects so that you can retrieve previous versions of them.
AWS S3 Storage Classes
Each object in Amazon S3 has a storage class associated with it. we choose one depending on our use case scenario and performance access requirements.
Amazon S3 offers the following storage classes for the objects that we store.
1.STANDARD — This storage class is ideal for performance-sensitive use cases and frequently accessed data. STANDARD is the default storage class; if you don’t specify storage class at the time that you upload an object, Amazon S3 assumes the STANDARD storage class.
2.STANDARD_IA — This storage class (IA, for infrequent access) is optimized for long-lived and less frequently accessed data, for example, backups and older data where the frequency of access has diminished, but the use case still demands high performance. The STANDARD_IA storage class is suitable for larger objects greater than 128 Kilobytes that you want to keep for at least 30 days.
3. GLACIER — The GLACIER storage class is suitable for archiving data where data access is infrequent. Archived objects are not available for real-time access. You must first restore the objects before you can access them.
4. REDUCED_REDUNDANCY — The Reduced Redundancy Storage (RRS) storage class is designed for noncritical, reproducible data stored at lower levels of redundancy than the STANDARD storage class, which reduces storage costs.

Lifecycle Management
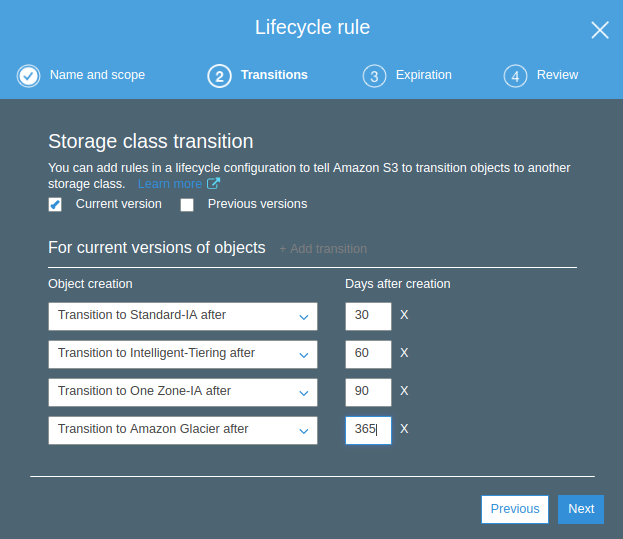
In lifecycle management, amazon s3 apply some set of rule to a group of an object or to bucket itself to move objects from one storage system to another and finally expiring it.we can define amazon s3 to tom move data between various storage class on defined schedule.
This manages to store data in a cost-effective way, there are two types of actionTaking the example to move data from one storage class to other.

>Transition Actions: With this action, we choose to move the object from one storage tier to another.

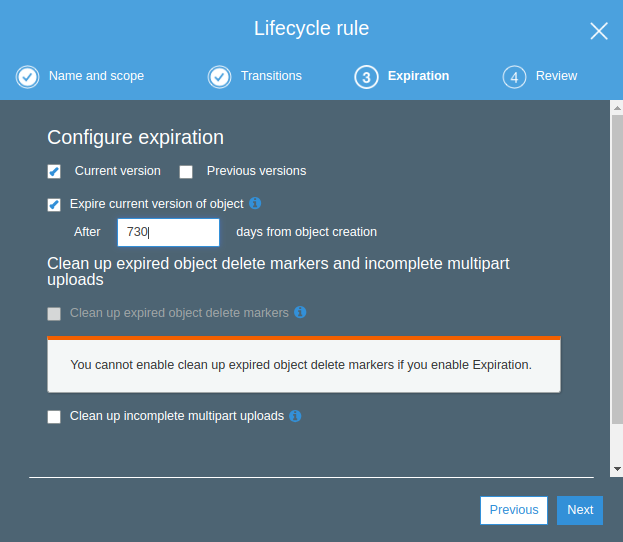
Lastly after 60 days data moved to the glacier which having at low-cost storage class in Amazon S3.
>Expirations Actions: Here Amazon S3 removes all objects in the bucket when a specified date or time period is over.
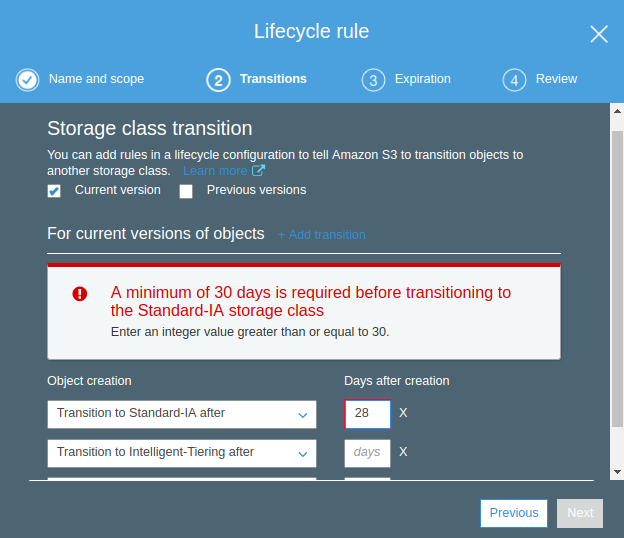
Creating Expiry Lifecycle.Minimum 30 days required before the transition to any other storage classExpire Lifecycle created



Bucket Policies
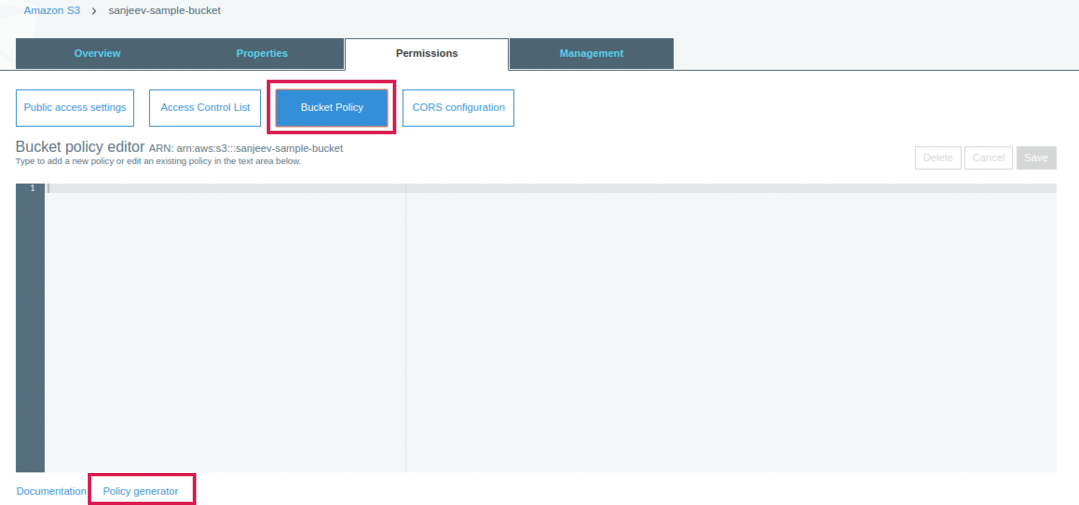
Bucket policy is written in JSON format so we can write same through policy generator “https://awspolicygen.s3.amazonaws.com/policygen.html”

we require Amazon resource name(ARN) on which bucket we have to implement policy.

Now policy in JSON format created.
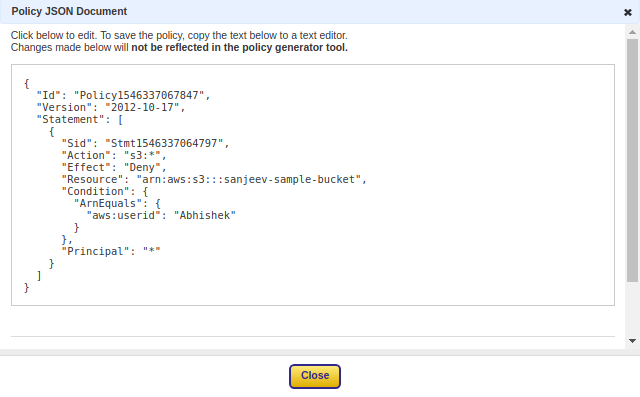
Lastly, copy this JSON in bucket policy and save.

Data protection
Amazon provides high security on data using the different method. Amazon protects data using 2 methods.
>Data Encryption: It refers to protection of data while being transferring, it happens in two different way.

>Versioning: It can be utilized to preserve, recover and restore the early version of every object we stored in Amazon S3 bucket. unintentional erase or overwrite can easily regain with versioning.Two different versions of the same image having same object id.
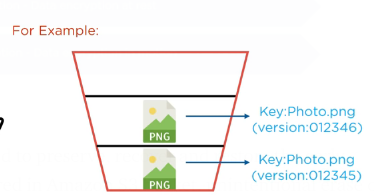
We need to first enable versioning.


Here we have three versions of the same file in the bucket we can roll back to the previous one using the same file.
Transfer acceleration
It enables fast, easy and secure transfer of a file over the long distance between client and S3 bucket.
The edge location around the world provided by Amazon cloud front are taken advantage of transfer acceleration.
It works via carrying data over an optimized network bridge that keep running between CloudFront and S3 location.
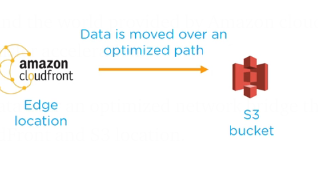
we can enable Transfer Acceleration by going into properties of the bucket.
Last updated